
Grep and Regular Expressions (Regex)
[Video uploading]
Grepp-y Regex-y Notes
We picked out recurring patterns and defined regex to match those individually; each one was validated against the dataset. Then we combined them in an OR condition so that grep would extract and and all matches. With the matches, we proceeded to sort the output and de-duplicate repeated terms.
# grep -oE <regex> <file>
# -o - only print the matching pattern (not entire line)
# -E - enabled extended regex (fancy syntax; in case it's needed)
# Match lines beginning with upper case + punctuation:
# RADIUS, OSPF, S.M.A.R.T. TCP/IP, and IS-IS
^[A-Z\./-]{2,10}
# Match lines beginning with uppercase->lowercase->uppercase letters:
# SaaS, PaaS, IaaS, IrDA
^[A-Z]{1,3}[a-z]{1,4}[A-Z]{1,4}
# Match lines beginning with lowercase->uppercase letters:
# exFAT, vNIC
^[a-z]{1,3}[A-Z]{1,4}
# Match lines beginning with uppercase->lowercase letters:
# IPSec
^[A-Z]{1,4}[a-z]{1,4}
# Match lines beginning with uppercase->digits:
# FAT32, AES128, MD5
^[A-Z]{2,4}[0-9]{1,3}
# We then need to glue these all together under a giant OR condition.
# (A|B|C|D|E) means "either A, B, C, D, or E"
# We move the ^ anchor ("line begins here) outside, since it's shared by all; no need to duplicate
# The \s at the end matches a space, making sure it's not a long word we're actually matching on
# Final result:
^([A-Z\./-]{2,10}|[A-Z]{1,3}[a-z]{1,4}[A-Z]{1,4}|[a-z]{1,3}[A-Z]{1,4}|[A-Z]{1,4}[a-z]{1,4}|[A-Z]{2,4}[0-9]{1,3})\s
# Then we must (potentially) remove trailing whitespace, sort, de-duplicate, and pipe into a file.
-
grep -oE "^([A-Z\./-]{2,10}|[A-Z]{1,3}[a-z]{1,4}[A-Z]{1,4}|[a-z]{1,3}[A-Z]{1,4}|[A-Z]{1,4}[a-z]{1,4}|[A-Z]{2,4}[0-9]{1,3})\s" \
comptia_kinda_clean.txt | \
sed 's/\s$//' | \
sort -u >> file
# | - take output and redirect to another command's input
# sed 's/\s$//' - if line ends ($) with a space (\s), replace it with nothing "//"
# sort -u - sort and de-duplicate lines
# >> file - redirect into a file
"Lectern" - Big Picture
I've been playing with OpenAI whisper for several months now, first to assist ESL college students with following the technical material we covering in our course. Since then I've been iterating on my "Lectern" Python script (working title; work in progress) and had good success improving its accuracy with technical content by:
- Adding the ability to summarize (via text prompt) the recording, and provide some acronyms it uses
- Sliding-scale high-pass/low-pass noise filter with 1 being very conservative (deep rumbles and shrill tones cut) and 5 more aggressive (ability to skip noise filter entirely for studio environments)
Quality-of-life improvements include:
- Ability to ingest pure audio or video files
- Model selection (e.g., tiny.en, medium.en)
- Choice of two subtitle formats (.srt and .vtt)
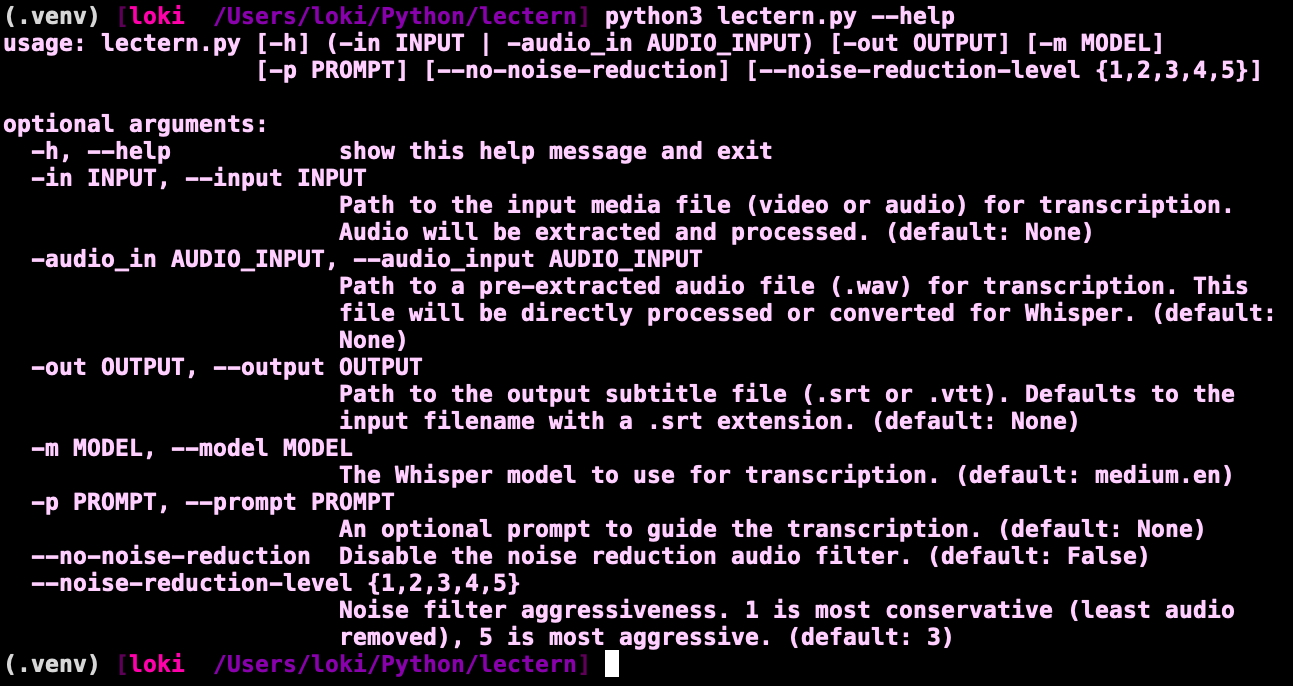
But it's still very much a work-in-progress. Next steps (in rough order of execution) are:
- Local pre-processing using OpenCV/OCR on video to detect themes/context over time. Subdivide video into several parts, transcribed individually with targeted keyword prompts (by way of OCR), and stitch transcription back together. Example:
- First section of class about TCP: detect keywords "MSS", "SYN", "ACK" in PowerPoint and prompt Whisper with these terms/acronyms.
- Next section about XYZ, detect XYZ keywords and feed into prompt for next batch of transcription.
- Maintain the context state for each video "section" or part
- Local post-processing against a IT terminology dictionary using existing Python libraries and dictionaries including the one I'm building
- Remote post-processing against a LLM as several API calls enriched with OpenCV/OCR context (text read from PowerPoint, websites, etc. in recordings).